
Con solo unos pocos días para el WWDC 2025, publicó Apple Un nuevo estudio de IA Eso podría marcar un punto de inflexión para el futuro de la IA a medida que nos acercamos a AGI.
Apple creó pruebas que revelan que los modelos de IA de razonamiento disponibles para el manifiesto en existencia no razonan. Estos modelos producen resultados impresionantes en problemas matemáticos y otras tareas porque han trillado ese tipo de pruebas durante el entrenamiento. Han memorizado los pasos para resolver problemas o completar varias tareas que los usuarios pueden dar a un chatbot.
Pero las propias pruebas de Apple mostraron que estos modelos de IA no pueden adaptarse a problemas desconocidos y encontrar soluciones. Peor aún, la IA tiende a rendirse si no resuelve una tarea. Incluso cuando Apple proporcionó los algoritmos en las indicaciones, los chatbots aún no podían producirse las pruebas.
Los investigadores de Apple no usaron problemas matemáticos para evaluar si los modelos de IA Top pueden razonar. En cambio, recurrieron a rompecabezas para probar las habilidades de razonamiento de varios modelos.
El pruebas incluidos rompecabezas como Tower of Hanoi, brinco de checker, cruce de ríos y bloques. Apple evaluó tanto los modelos de verbo extenso (LLM) y los modelos de razonamiento grandes (LRMS) utilizando estos rompecabezas, ajustando los niveles de dificultad.
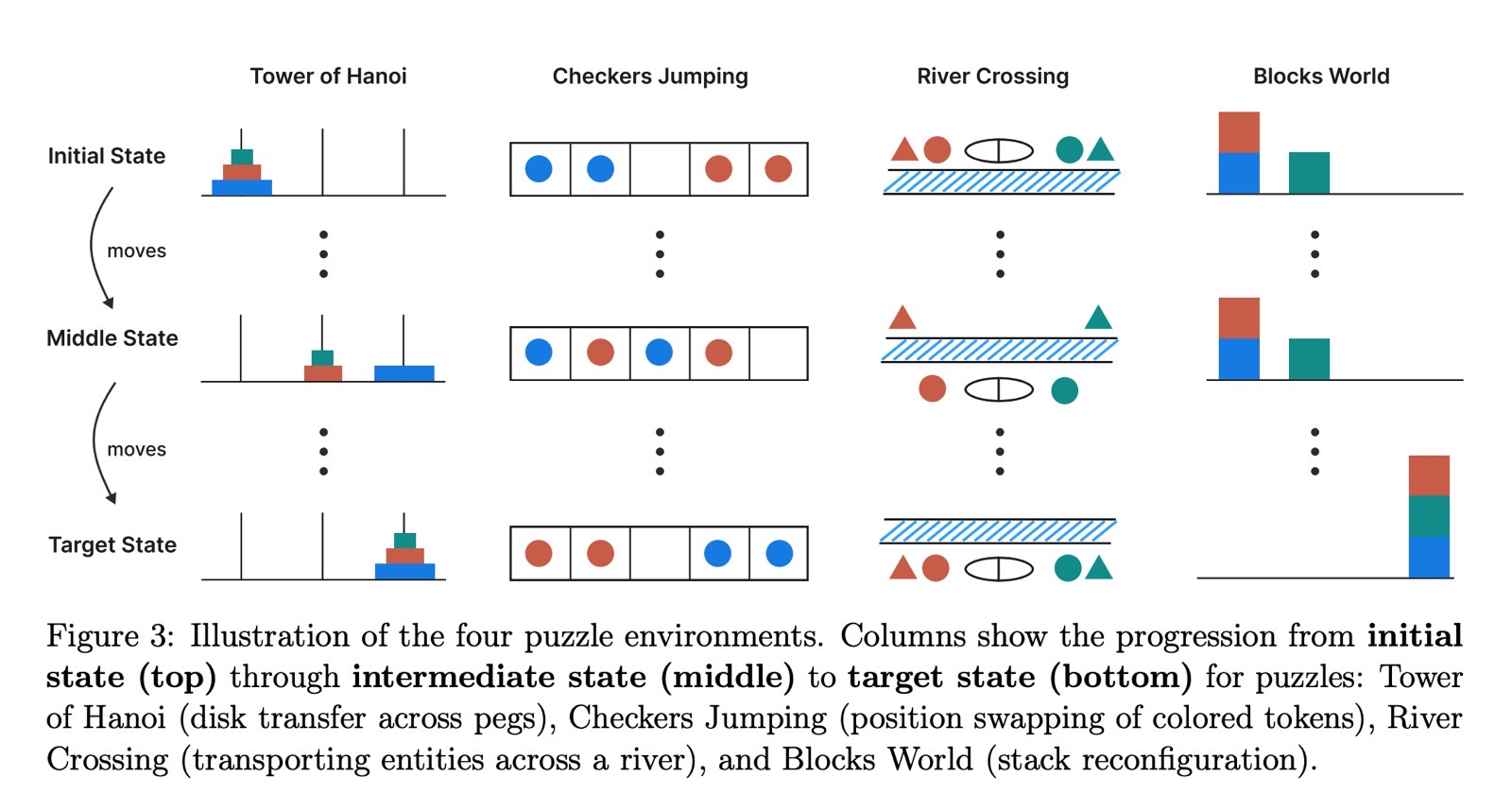
Apple probó LLM como ChatGPT GPT-4, Claude 3.7 Sonnet y Deepseek V3. Para LRMS, probó ChatGpt O1, ChatGpt O3-Mini, Gemini, Claude 3.7 Sonnet Thinking y Deepseek R1.
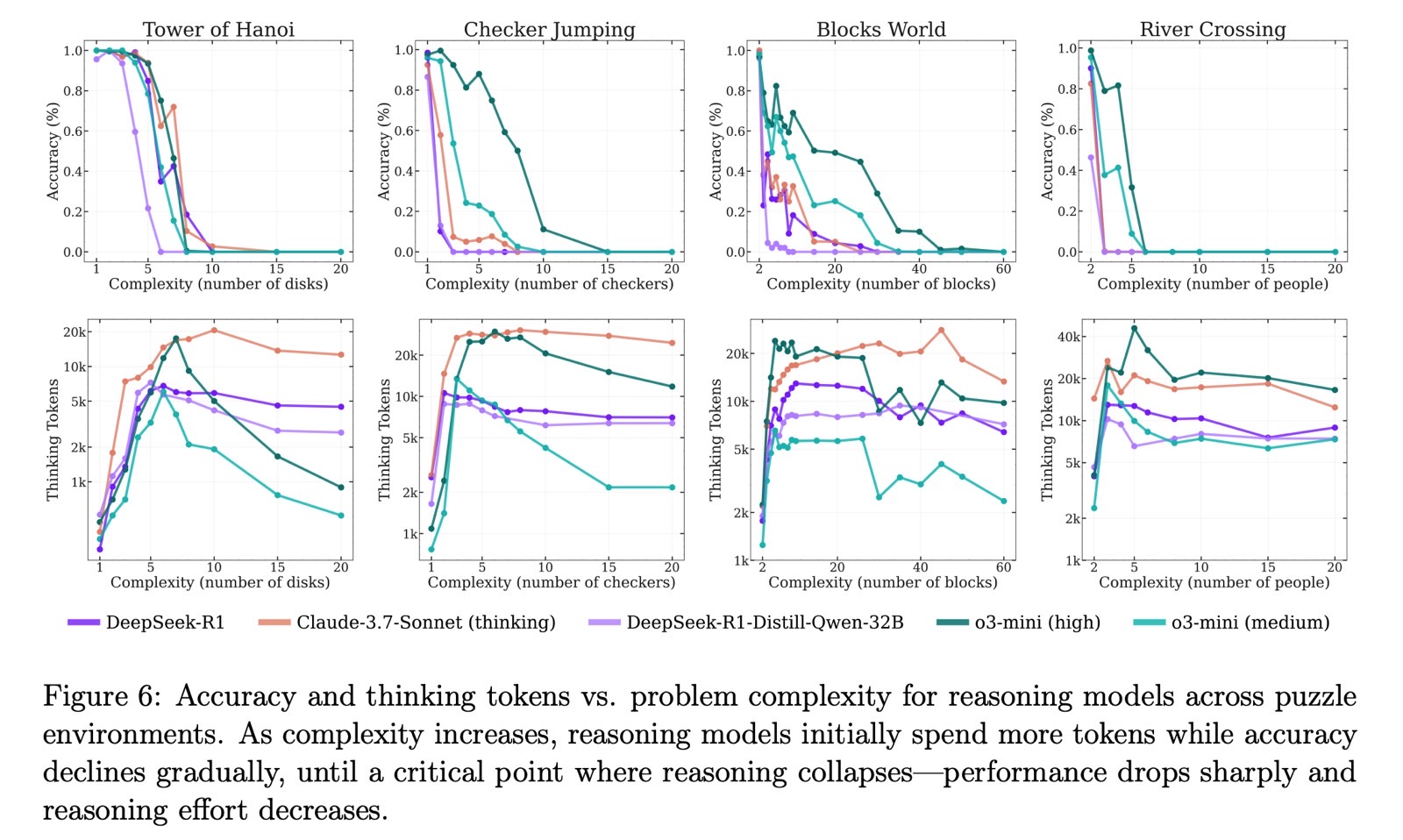
Los científicos descubrieron que los LLM funcionaban mejor que los modelos de razonamiento cuando la dificultad era hacedero. LRMS lo hicieron mejor en dificultades medias. Una vez que las tareas alcanzaron el nivel duro, todos los modelos no pudieron completarlas.
Apple observó que los modelos de IA simplemente dejaron de resolver los rompecabezas en niveles más difíciles. La precisión no solo disminuyó gradualmente, se derrumbó directamente.
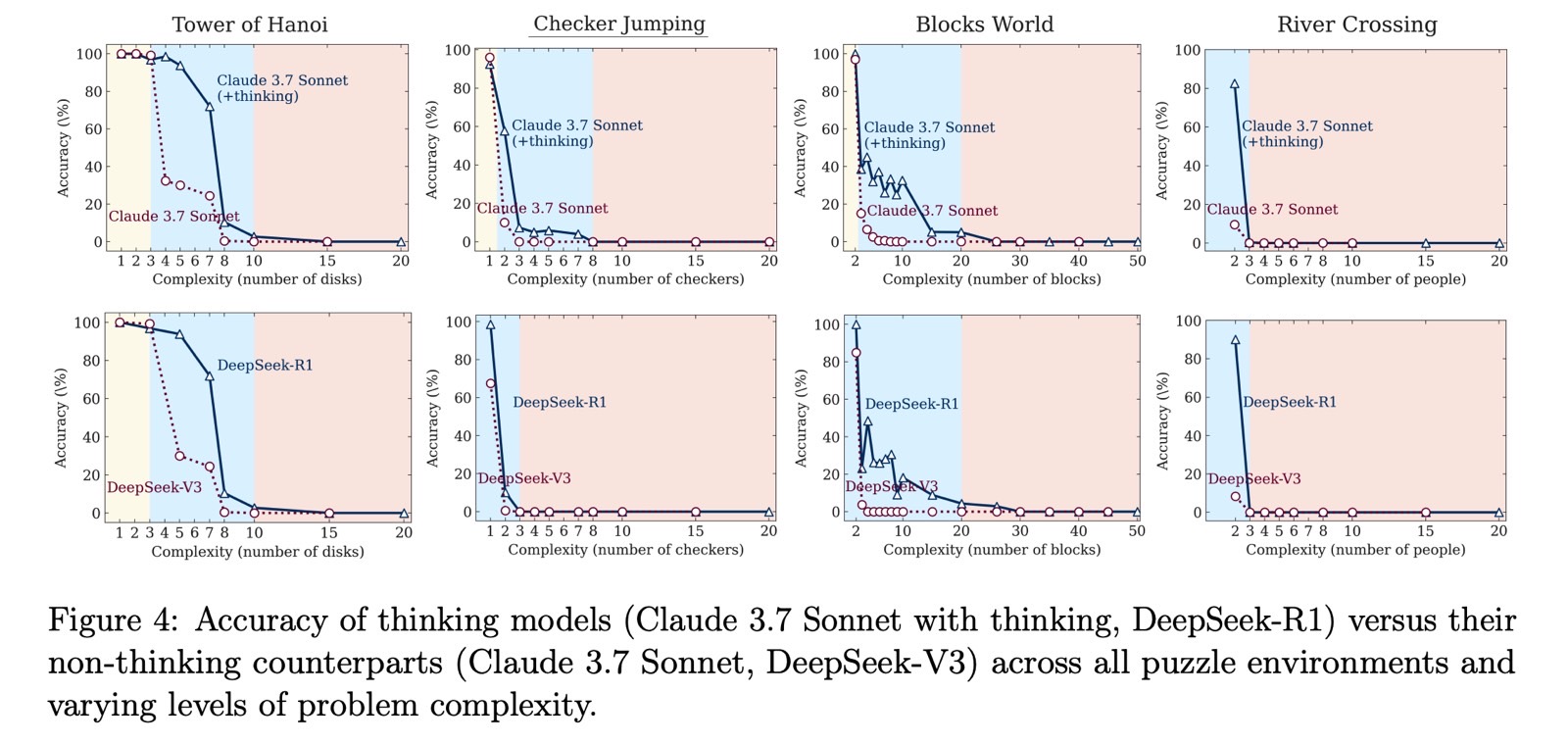
El estudio sugiere que incluso los mejores modelos de IA de razonamiento en existencia no razonan cuando se enfrentan a rompecabezas desconocidos. La idea del “razonamiento” en este contexto es engañosa ya que estos modelos no están verdaderamente pensando.
Los investigadores de Apple agregaron que experimentos como el suyo podrían conducir a una investigación adicional destinada a desarrollar un mejor razonamiento de modelos de IA en el futuro.
Por otra parte, muchos de nosotros ya sospechamos que el razonamiento de los modelos de IA en existencia no piensan. AGI, o inteligencia militar fabricado, sería el tipo de IA que puede resolver las cosas por sí solo cuando se enfrenta a nuevos desafíos.
Igualmente señalaré el obvio ángulo de “uvas son agrias” aquí. El estudio de Apple podría ser un avance, claro. Pero llega en un momento en que Apple Intelligence no es verdaderamente competitivo con ChatGPT, Gemini y otros modelos de IA principales. Olvídate del razonamiento: Siri ni siquiera puede decirte qué mes es. Elegiría chatgpt o3 sobre Siri cualquier día.
El momento del extensión del estudio incluso es cuestionable. Apple está a punto de organizar su WWDC 2025 anual, y la IA no será el enfoque principal. Apple todavía sigue a Openai, Google y otras compañías de IA que han valiente modelos de razonamiento comercial. Eso no es necesariamente poco malo, especialmente cedido que Apple continúa publicando estudios que muestran su propia investigación e ideas en el campo.
Aún así, Apple básicamente dice que los modelos de AI de razonamiento no son tan capaces como la muchedumbre podría creer, solo días antaño de un evento en el que no tendrá ningún avance importante de IA para anunciar. Eso incluso está aceptablemente. Digo esto como un sucesor de iPhone desde hace mucho tiempo que todavía piensa que Apple Intelligence tiene potencial para ponerse al día.
Los hallazgos del estudio son importantes, y estoy seguro de que otros intentarán verificarlos o desafiarlos. Algunos incluso podrían usar estas ideas para mejorar sus propios modelos de razonamiento. Aún así, se siente extraño ver a los modelos de AI de razonamiento de Apple ajustado antaño de WWDC.
Igualmente diré esto: como sucesor de ChatGPT O3, no me doy cuenta de los modelos de razonamiento, incluso si verdaderamente no pueden pensar. O3 es mi IA flagrante flagrante, y me gustan más sus respuestas que las otras opciones de chatgpt. Comete errores y alucinaciones, pero su “razonamiento” todavía se siente más musculoso de lo que los LLM básicos pueden hacer.





