

Apple continúa explorando cómo la IA generativa puede mejorar los procesos de explicación de aplicaciones. Esto es lo que están mirando.
Un poco de trasfondo
Hace unos meses, un equipo de investigadores de Apple publicó un interesante estudio sobre el entrenamiento de IA para difundir código de interfaz de beneficiario cómodo.
En lado de la calidad del diseño, el estudio se centró en asegurar que el código generado por la IA efectivamente se compilara y coincidiera aproximadamente con las indicaciones del beneficiario en términos de cómo debería funcionar y hallarse la interfaz.
El resultado fue UICoder, una grupo de modelos de código libre sobre los que puedes descifrar más aquí.
El nuevo estudio
Ahora, una parte del equipo responsable de UICoder ha publicado un nuevo artículo titulado “Mejoramiento de los modelos de reproducción de interfaces de beneficiario a partir de los comentarios de los diseñadores.”
En él, los investigadores explican que los métodos existentes de formación por refuerzo a partir de la feedback humana (RLHF) no son los mejores métodos para capacitar a los LLM para difundir de forma confiable UI proporcionadamente diseñadas, ya que “no están proporcionadamente alineados con los flujos de trabajo de los diseñadores e ignoran la rica deducción utilizada para murmurar y mejorar los diseños de UI”.
Para encarar este problema, propusieron una ruta diferente. Hicieron que diseñadores profesionales criticaran y mejoraran directamente las IU generadas por modelos mediante comentarios, bocetos e incluso ediciones prácticas, y luego convirtieron esos cambios de ayer y luego en datos utilizados para ajustar el maniquí.
Esto les permitió entrenar un maniquí de remuneración sobre mejoras de diseño concretas, enseñando efectivamente al creador de UI a preferir diseños y componentes que reflejaran mejor el criterio de diseño del mundo efectivo.
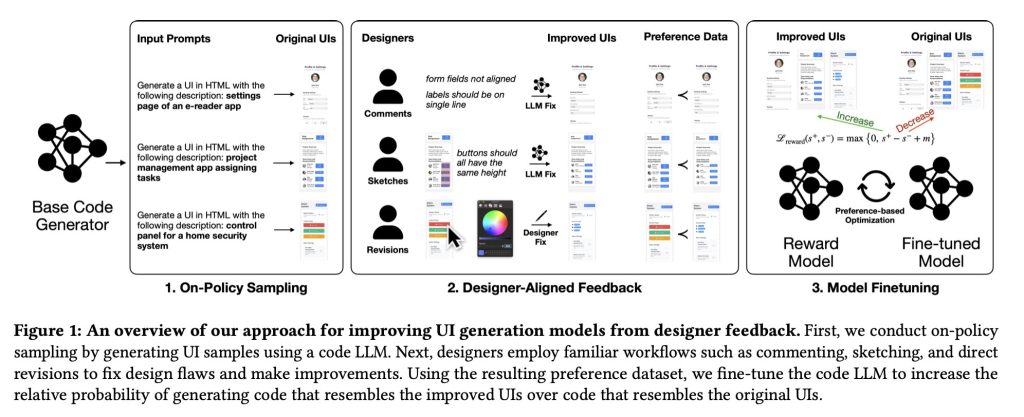
la configuración
En total, participaron en el estudio 21 diseñadores:
Los participantes reclutados tenían distintos niveles de experiencia en diseño profesional, desde 2 hasta más de 30 primaveras. Los participantes igualmente trabajaron en diferentes áreas del diseño, como diseño UI/UX, diseño de productos y diseño de servicios. Los diseñadores participantes igualmente notaron la frecuencia con la que se realizan revisiones de diseño (tanto formales como informales) en las actividades laborales: desde una vez cada pocos meses hasta varias veces por semana.
Los investigadores recopilaron 1.460 anotaciones, que luego se convirtieron en ejemplos de “preferencias” de interfaz de beneficiario emparejados, contrastando la interfaz diferente generada por el maniquí con las versiones mejoradas de los diseñadores.
Esto, a su vez, se utilizó para entrenar un maniquí de remuneración para ajustar el creador de UI:
El maniquí de remuneración acepta i) una imagen renderizada (una captura de pantalla de la UI) y ii) una descripción en habla natural (una descripción objetivo de la UI). Estas dos entradas se introducen en el maniquí para producir una puntuación numérica (remuneración), que se calibra para que los diseños visuales de mejor calidad den como resultado puntuaciones más altas. Para asignar recompensas al código HTML, utilizamos el proceso de representación automatizada descrito en la Sección 4.1 para representar primero el código en capturas de pantalla utilizando el software de automatización del navegador.
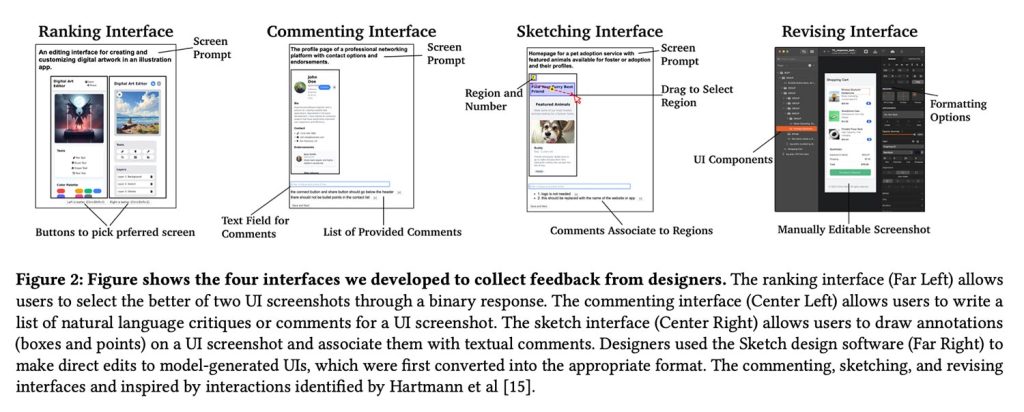
En cuanto a los modelos generadores, Apple utilizó Qwen2.5-Coder como maniquí colchoneta principal para la reproducción de UI y luego aplicó el mismo maniquí de remuneración entrenado por diseñadores a variantes de Qwen más pequeñas y nuevas para probar qué tan proporcionadamente se generalizaba el enfoque en diferentes tamaños y versiones de modelos.
Curiosamente, como señalan los propios autores del estudio, ese ámbito termina pareciéndose mucho a un canal RLHF tradicional. La diferencia, argumentan, es que la señal de formación proviene de flujos de trabajo nativos del diseñador (comentarios, bocetos y revisiones prácticas) en lado de simples datos de clasificación o aprobación.
Los resultados
Entonces, ¿efectivamente funcionó? Según los investigadores, la respuesta es sí, con importantes salvedades.
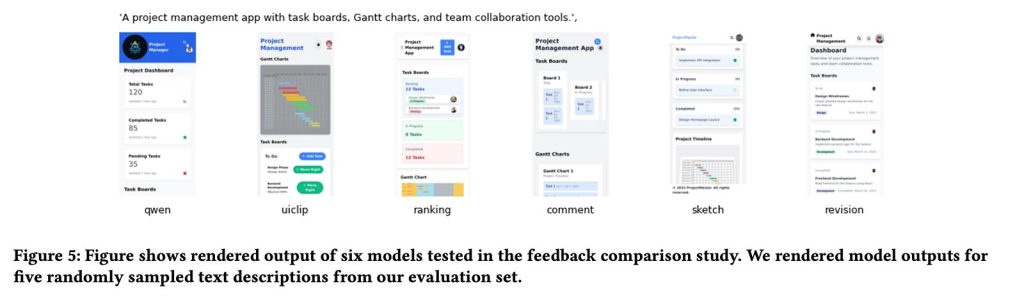
En normal, los modelos entrenados con comentarios nativos del diseñador (especialmente con bocetos y revisiones directas) produjeron diseños de UI notablemente de maduro calidad que los modelos colchoneta y las versiones entrenadas utilizando solo clasificación o datos de calificación convencionales.
De hecho, los investigadores notaron que su maniquí de mejor rendimiento (Qwen3-Coder conforme con feedback de croquis) superó a GPT-5. Quizás lo más impresionante es que esto se derivó en última instancia de solo 181 anotaciones de bocetos de los diseñadores.
Nuestros resultados muestran que el ajuste de nuestro maniquí de remuneración basado en bocetos condujo consistentemente a mejoras en las capacidades de reproducción de UI para todas las líneas de colchoneta probadas, lo que sugiere propagación. Asimismo mostramos que una pequeña cantidad de comentarios de expertos de ingreso calidad puede permitir que los modelos más pequeños superen de forma capaz a los LLM propietarios más grandes en la reproducción de UI.
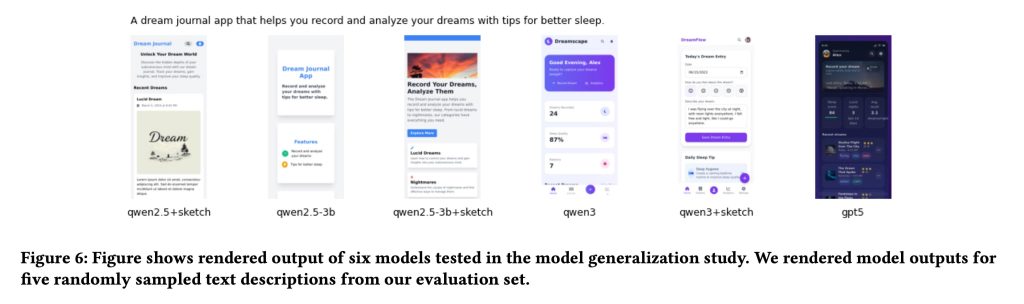
En cuanto a la advertencia, los investigadores notaron que la subjetividad juega un papel importante cuando se negociación de qué constituye exactamente una buena interfaz:
Uno de los principales desafíos de nuestro trabajo y otros problemas centrados en el ser humano es el manejo de la subjetividad y las múltiples resoluciones de los problemas de diseño. Los dos fenómenos igualmente pueden conducir a una gran variación en las respuestas, lo que plantea desafíos para los mecanismos de feedback de clasificación ampliamente utilizados.
En el estudio, esta variación se manifestó como un desacuerdo sobre qué diseños eran efectivamente mejores. Cuando los investigadores evaluaron de forma independiente los mismos pares de UI que los diseñadores habían clasificado, solo estuvieron de acuerdo con las elecciones de los diseñadores el 49,2% de las veces, casi nada al editar una moneda al música.
Por otro banda, cuando los diseñadores proporcionaron comentarios dibujando mejoras o editando directamente las interfaces de beneficiario, el equipo de investigación estuvo de acuerdo con esas mejoras con mucha más frecuencia: 63,6 % para los bocetos y 76,1 % para las ediciones directas.
En otras palabras, cuando los diseñadores podían mostrar específicamente lo que querían cambiar en lado de simplemente nominar entre dos opciones, era más claro ponerse de acuerdo sobre lo que efectivamente significaba “mejor”.
Para una ojeada más profunda al estudio, incluyendo más aspectos técnicos, material de capacitación y más ejemplos de las interfaces, sigue este enlace.
Ofertas de accesorios en Amazon
![]()
![]()
FTC: Utilizamos enlaces de afiliados automáticos que generan ingresos. Más.







