
Para crear números típicos, el equipo que realizó el estudio rastreó las solicitudes y el hardware que les sirvió durante un período de 24 horas, así como el tiempo de inactividad para ese hardware. Esto les da una estimación de energía por solicitud, que difiere en función del maniquí que se utiliza. Para cada día, identifican el aviso mediano y lo usan para calcular el impacto ambiental.
Que señala desaprobación
Usando esas estimaciones, encuentran que el impacto de una solicitud de texto individual es conveniente pequeño. “Estimamos la mediana del mensaje de texto de Gemini Apps usa 0.24 vatios de energía de energía, emite 0.03 gramos de dióxido de carbono equivalente (GCO2E) y consume 0.26 mililitros (o más o menos de cinco gotas) de agua”, concluyen. Para poner eso en contexto, estiman que el uso de energía es similar a unos nueve segundos de visualización de televisión.
La mala nueva es que el comba de solicitudes es sin duda muy detención. La compañía ha optado por ejecutar una operación de IA con cada solicitud de búsqueda, una demanda de cuenta que simplemente no existía hace un par de primaveras. Entonces, si correctamente el impacto individual es pequeño, es probable que el costo acumulativo sea considerable.
¿La buena nueva? Hace solo un año, hubiera sido mucho, mucho peor.
Poco de esto se proxenetismo de circunstancias. Con el auge de la energía solar en los EE. UU. Y en otros lugares, ha sido más hacedero para Google organizar la energía renovable. Como resultado, las emisiones de carbono por mecanismo de energía consumida vieron una reducción de 1.4x durante el año pasado. Pero las mayores victorias han sido en el costado del software, donde diferentes enfoques han llevado a una reducción de 33x en la energía consumida por aviso.
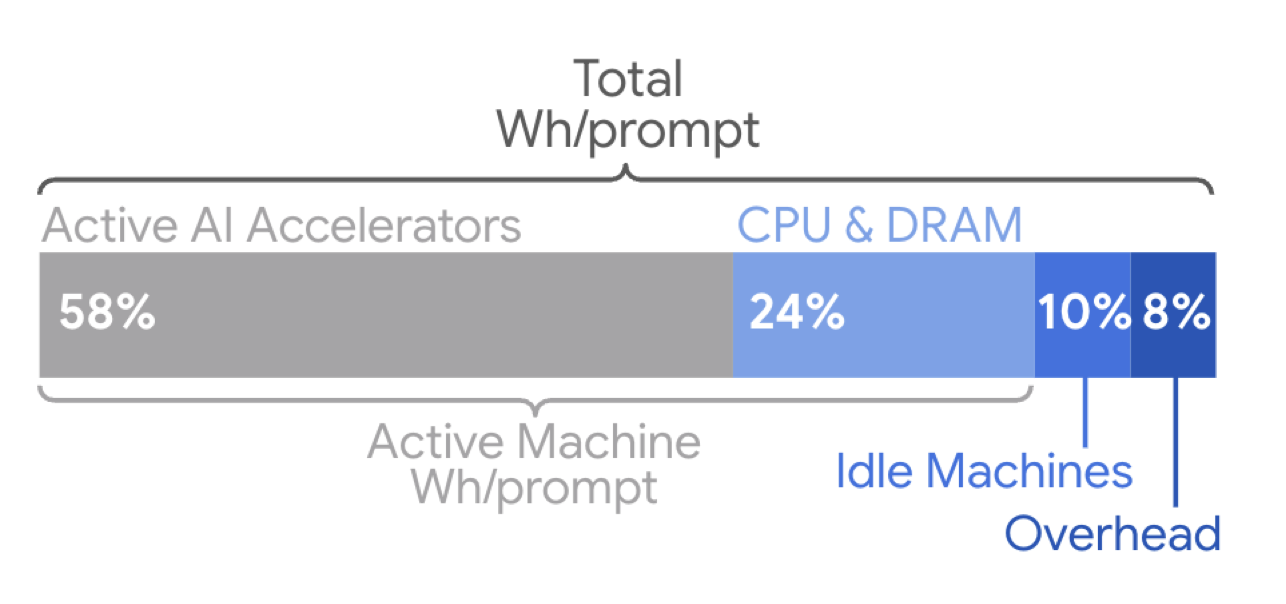
La anciano parte del uso de energía para servir solicitudes de IA proviene del tiempo dedicado a los chips aceleradores personalizados.
Crédito: Elsworth, et. Alabama.
El equipo de Google describe una serie de optimizaciones que la compañía ha hecho que contribuyen a esto. Uno es un enfoque denominado mezcla de expertos, que implica descubrir cómo activar solo la porción de un maniquí de IA necesario para manejar solicitudes específicas, que pueden eliminar las micción computacionales en un hacedor de 10 a 100. Han desarrollado una serie de versiones compactas de su maniquí principal, que incluso reducen la carga computacional. La gobierno del centro de datos incluso juega un papel, ya que la compañía puede comprobar de que cualquier hardware activo se utilice completamente, al tiempo que permite que el resto permanezca en un estado de descenso potencia.





