
Otro día, otro maniquí de IA de Google. Google positivamente ha estado lanzando nuevas herramientas de inteligencia químico por último, y acaba de exhalar Gemini 3 en noviembre. Hoy, está llevando el maniquí insignia a la lectura 3.1. el nuevo Géminis 3.1 Pro se está implementando (en lectura preliminar) para desarrolladores y consumidores hoy con la promesa de mejores capacidades de razonamiento y resolución de problemas.
Google anunció mejoras en su aparejo Deep Think la semana pasada y, aparentemente, la “inteligencia central” detrás de esa modernización fue Gemini 3.1 Pro. Como es habitual, el anuncio del postrero maniquí de Google viene con una gran cantidad de puntos de relato que muestran mejoras en su mayoría modestas. En el popular postrero examen de la humanidad, que evalúa conocimientos avanzados de dominios específicos, Gemini 3.1 Pro obtuvo una puntuación récord del 44,4 por ciento. Gemini 3 Pro logró el 37,5 por ciento, mientras que GPT 5.2 de OpenAI obtuvo el 34,5 por ciento.
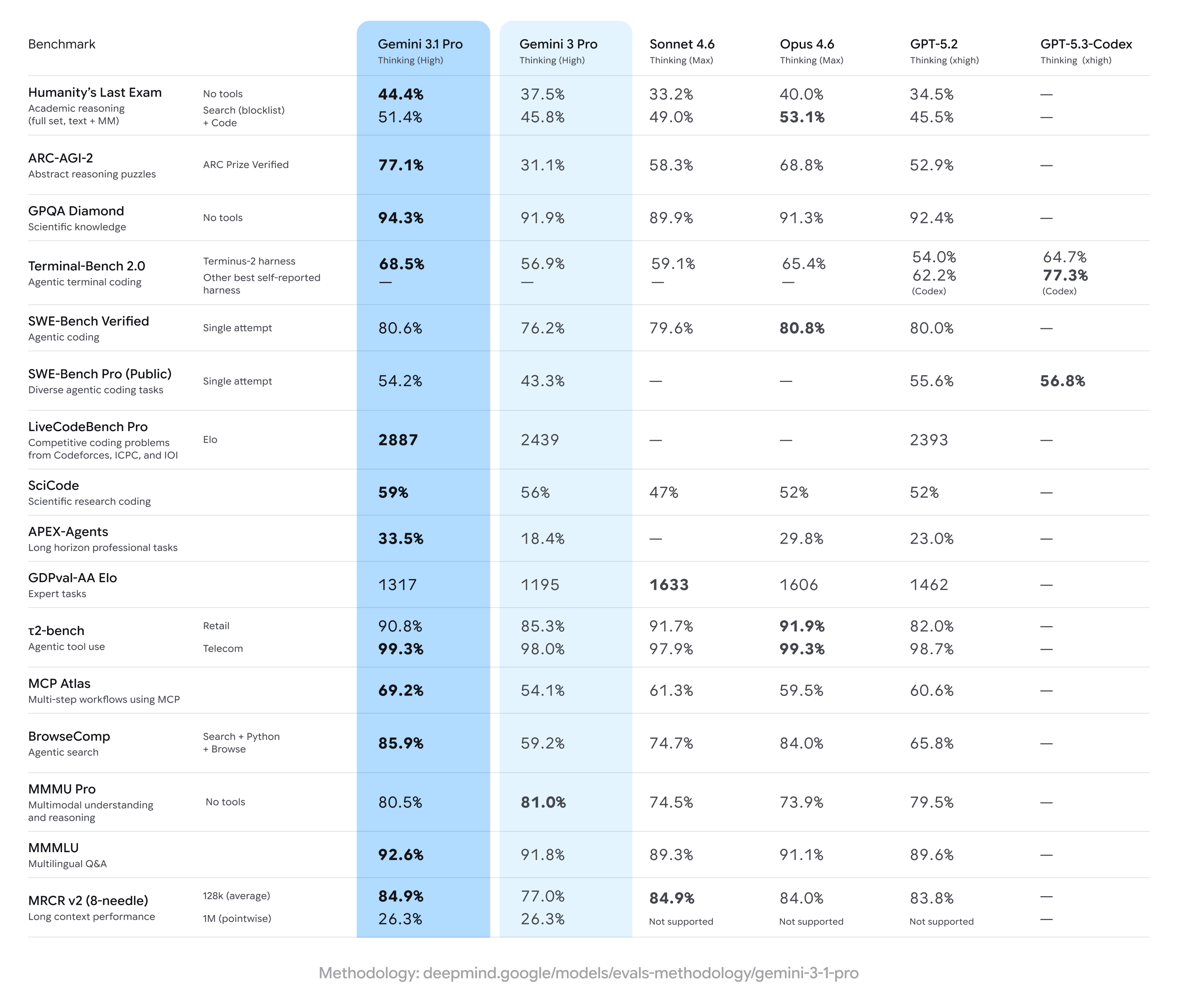
Google asimismo destaca la alivio del maniquí en ARC-AGI-2, que presenta nuevos problemas lógicos que no se pueden entrenar directamente en una IA. Gemini 3 quedó un poco detrás en esta evaluación, alcanzando al punto que el 31,1 por ciento frente a puntuaciones de 50 y 60 para los modelos de la competencia. Gemini 3.1 Pro duplica con creces la puntuación de Google, alcanzando un elevado 77,1 por ciento.
Google a menudo se jacta cuando bichero nuevos modelos de que ya han llegado a la cima del mercado. Arena tabla de clasificación (anteriormente LM Arena), pero ese no es el caso esta vez. Para texto, Claude Opus 4.6 supera al nuevo Gemini por cuatro puntos con 1504. Para código, Opus 4.6, Opus 4.5 y GPT 5.2 High van un poco más por delante de Gemini 3.1 Pro. Sin incautación, vale la pena señalar que la clasificación de la Arena se apoyo en vibraciones. Los usuarios votan sobre los resultados que más les gustan, lo que puede remunerar los resultados que parecen correctos independientemente de si lo son.





