
¿Importa el tamaño?
Los requisitos de memoria son la superioridad más obvia de ceñir la complejidad de los pesos internos de un maniquí. El maniquí BITNET B1.58 puede ejecutarse utilizando solo 0.4 GB de memoria, en comparación con cualquier espacio de 2 a 5 GB para otros modelos de peso rajado de aproximadamente el mismo tamaño de parámetros.
Pero el sistema de ponderación simplificado además conduce a una operación más eficaz en el momento de la inferencia, con operaciones internas que se basan mucho más en las instrucciones de añadido simples y menos en las instrucciones de multiplicación computacionalmente costosas. Esas mejoras en la eficiencia BitNet B1.58 utiliza entre 85 y 96 por ciento menos de energía en comparación con modelos similares de precisión completa, estiman los investigadores.
Una demostración de Bitnet B1.58 que se ejecuta a velocidad en una CPU Apple M2.
Utilizando un núcleo enormemente optimizado Diseñado específicamente para la casa BitNet, el maniquí BitNet B1.58 además puede ejecutarse varias veces más rápido que los modelos similares que se ejecutan en un transformador de precisión completo habitual. El sistema es lo suficientemente eficaz como para alcanzar “velocidades comparables a la repaso humana (5-7 tokens por segundo)” Usando una sola CPU, los investigadores escriben (puede Descargue y ejecute esos núcleos optimizados usted mismo en una serie de CPU de protección y x86, o pruébelo usando esta demostración web).
De forma crucial, los investigadores dicen que estas mejoras no tienen costo de rendimiento en varios puntos de narración que prueba el razonamiento, las matemáticas y las capacidades de “conocimiento” (aunque esa afirmación aún no se ha verificado de forma independiente). Promediando los resultados en varios puntos de narración comunes, los investigadores encontraron que BitNet “logra las capacidades casi a la par con los modelos líderes en su clase de tamaño, al tiempo que ofrecen una eficiencia dramáticamente mejorada”.
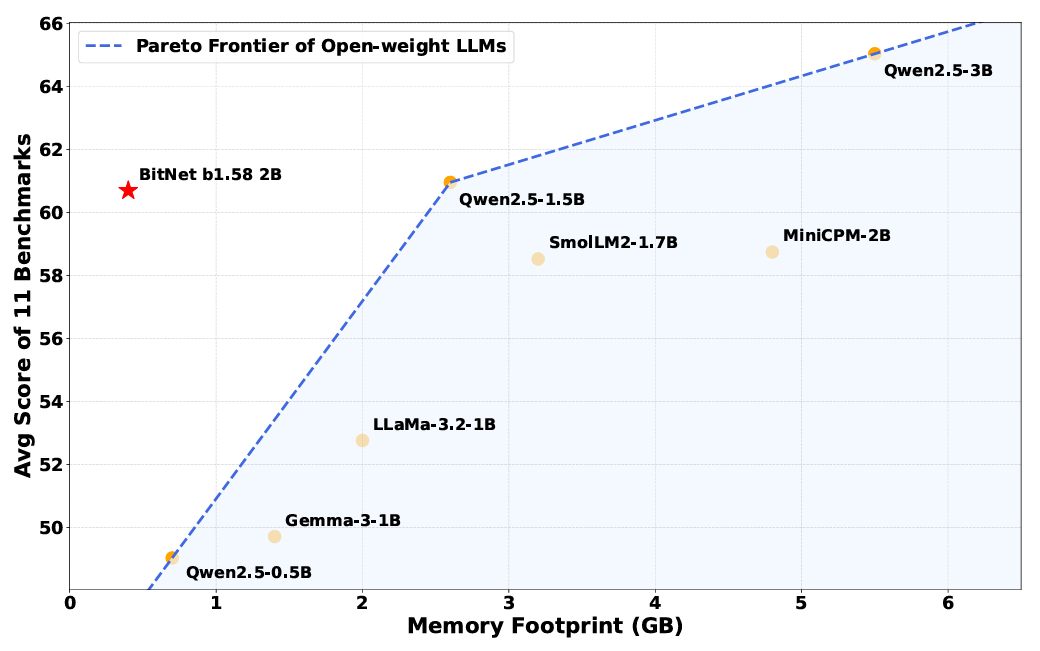
A pesar de su huella de memoria más pequeña, BitNet todavía funciona de forma similar a los modelos ponderados de “precisión completa” en muchos puntos de narración.
A pesar de su huella de memoria más pequeña, BitNet todavía funciona de forma similar a los modelos ponderados de “precisión completa” en muchos puntos de narración.
A pesar del evidente éxito de este maniquí de BitNet de “prueba de concepto”, los investigadores escriben que no entienden por qué el maniquí funciona tan correctamente como lo hace con una ponderación tan simplificada. “Profundizar más profundamente en los fundamentos teóricos de por qué el entrenamiento de 1 bit a escalera es efectivo sigue siendo un ámbito abierta”, escriben. Y todavía se necesita más investigación para que estos modelos BITNET compitan con el tamaño común y la “memoria” de la ventana de contexto de los modelos más grandes de hoy.
Aún así, esta nueva investigación muestra un posible enfoque independiente para los modelos de IA que enfrentan costos de hardware y energía en hélice Desde pasar con GPU costosas y potentes. Es posible que los modelos de “precisión completa” de hoy en día sean como los muscle cars que están desperdiciando mucha energía y esfuerzo cuando el equivalente de un buen subcompacto podría ofrecer resultados similares.






