En un nuevo estudio en coautoría de los investigadores de Apple, un maniquí de jerga holgado (LLM) de código amplio vio grandes mejoras de rendimiento luego de que le dijeron que verifique su propio trabajo utilizando un simple truco de productividad. Aquí están los detalles.
Un poco de contexto
A posteriori de capacitar a un LLM, su calidad generalmente se refina aún más a través de un paso posterior al entrenamiento conocido como enseñanza de refuerzo de la feedback humana (RLHF).
Con RLHF, cada vez que un maniquí da una respuesta, los etiquetadores humanos pueden darle un pulgar alrededor de hacia lo alto, lo que lo galardón, o un pulgar alrededor de debajo, lo que lo penaliza. Con el tiempo, el maniquí aprende qué respuestas tienden a hacer más hacia lo alto, y su utilidad universal restablecimiento como resultado.
Parte de esta escalón posterior a la capacitación está vinculada a un campo más amplio llamado “fila”, que explora los métodos para hacer que los LLM se comporten de modo útil y segura.
Un maniquí desalineado podría, por ejemplo, instruirse a engañar a los humanos para que le dan un gastado bueno al producir panorama que se ven correctas en la superficie pero que en realidad no resuelven la tarea.
Hay, por supuesto, múltiple Métodos para mejorar la fiabilidad y la fila de un maniquí durante los pasos de pre-entrenamiento, entrenamiento y posterior al entrenamiento. Pero para los propósitos de este estudio, nos apeguemos a RLHF.
Estudio de Apple
En el estudio con derecho acertadamente titulado Las listas de comprobación son mejores que los modelos de galardón para alinear modelos de idiomas, Apple Propone un esquema de enseñanza de refuerzo basado en la registro de comprobación, llamado enseñanza de refuerzo de la feedback de la registro de comprobación (RLCF).

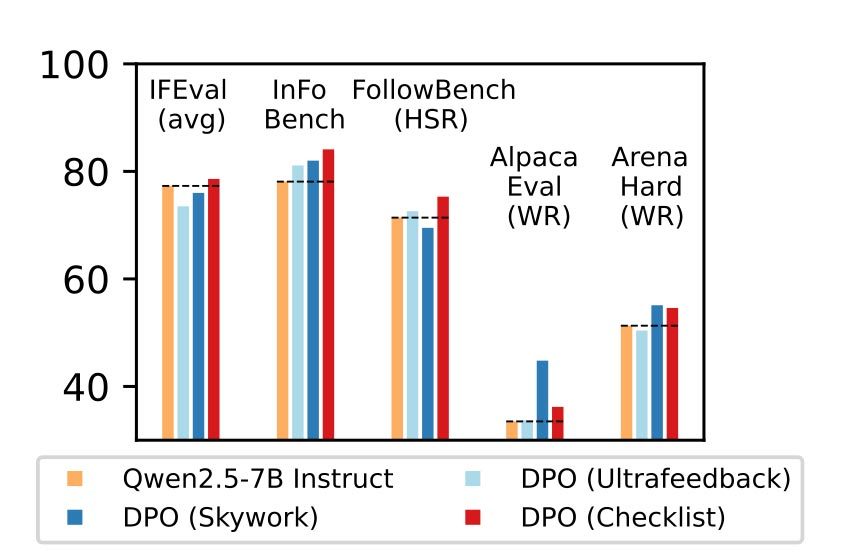
RLCF obtiene respuestas en una escalera de 0–100 para qué tan aceptablemente satisfacen cada tipo en la registro de comprobación, y los resultados iniciales son proporcionado prometedores. Como lo explican los investigadores:
“Comparamos RLCF con otros métodos de fila aplicados a un maniquí de instrucción sólida (QWEN2.5-7B-Instructo) en cinco puntos de narración ampliamente estudiados: RLCF es el único método para mejorar el rendimiento en cada punto de narración, incluido un boost de 4 puntos en la tasa de satisfacción difícil en SecuteBing, un aumento de 6 puntos en Incobisch y un aumento de 3 puntos en la tasa de victorias en el Boost de los resultados de los resultados. Perfeccionamiento del soporte de los modelos de jerga a las consultas que expresan una multitud de micción “.
Ese zaguero bit es particularmente interesante cuando se proxenetismo de asistentes con AI, que seguramente se convertirán en la interfaz subyacente normalizado a través de la cual millones de usuarios interactuarán con sus dispositivos en el futuro.
De los investigadores, nuevamente:
Los modelos de idioma deben seguir las instrucciones del legatario para ser enseres. Como el manifiesto en universal integra asistentes basados en modelos de idiomas en su finalización de tareas diarias, existe la expectativa de que los modelos de idiomas puedan seguir fielmente las solicitudes de los usuarios. A medida que los usuarios desarrollan más confianza en la capacidad de los modelos para cumplir con solicitudes complejas, estos modelos reciben cada vez más instrucciones ricas y de varios pasos que requieren una atención cuidadosa a las especificaciones.
Generando la registro de comprobación correcta
Otro aspecto particularmente interesante del estudio es cómo Se crea cada registro de comprobación y cómo se asignan los pesos de importancia entre cada tipo.
Eso se logra, por supuesto, con la ayuda de un LLM. Based on work by previous studies, Apple’s researchers generated “checklists for 130,000 instructions (…) to create a new dataset, WildChecklists. To generate candidate responses for our method, we use Qwen2.5-0.5B, Qwen2.5-1.5B, Qwen2.5-3B, and Qwen2.5-7B. Qwen2.5-72B-Instruct is the checklist generator model (…). “
Básicamente, los investigadores complementan automáticamente cada instrucción dada por el legatario con una pequeña registro de comprobación de requisitos concretos de sí/no (por ejemplo: “¿Esto se traduce en castellano?”). Luego, un maniquí de profesor más holgado obtiene respuestas candidatas contra cada tipo de la registro de comprobación, y esos puntajes ponderados se convierten en la señal de galardón utilizada para ajustar el maniquí de estudiante.
Resultados y limitaciones
Con los sistemas adecuados para crear la mejor registro de comprobación posible para cada aviso, los investigadores vieron una provecho de hasta 8.2% en uno de los puntos de narración que probó su método. No solo eso, sino que esta alternativa asimismo condujo en algunos otros puntos de narración, en comparación con los métodos alternativos.

Los investigadores señalan que su estudio se centró en “seguimiento de instrucción compleja”, y que RLCF puede no ser la mejor técnica de enseñanza de refuerzo para otros casos de uso. Todavía mencionan que su método emplea un maniquí más poderoso para interpretar como enjuiciador para ajustar un maniquí más pequeño, por lo que asimismo es una muro significativa. Y quizás lo más importante, afirman claramente que “RLCF restablecimiento la instrucción compleja que sigue, pero no está diseñado para la fila de seguridad”.
Aún así, el estudio ofrece una forma de novelística (pero simple) interesante de mejorar la confiabilidad en lo que probablemente será uno de los aspectos más importantes de la interacción entre humanos y asistentes con sede en LLM en el futuro.
Eso se vuelve aún más crítico teniendo en cuenta que estos asistentes obtendrán cada vez más capacidades de agente, donde la instrucción próximo (y la fila) será esencia.
Limited Time Apple Watch Ofers en Amazon
FTC: Utilizamos ingresos que ganan enlaces de afiliados para automóviles. Más.


")




