

Apple dejó caer un Nuevo maniquí de IA en la cara abrazada con un desvío interesante. En circunscripción de escribir código como LLM tradicional generan texto (de izquierda a derecha, de en lo alto a debajo), todavía puede escribir fuera de orden y mejorar múltiples fragmentos a la vez.
El resultado es una vivientes de código más rápida, a un rendimiento que rivaliza con los modelos de codificación de código libre. Así es como funciona.
Los bits nerd
Aquí hay algunos conceptos (demasiado simplificados, en nombre de la eficiencia) que son importantes para entender antaño de que podamos seguir delante.
Autorregresión
Tradicionalmente, la mayoría de los LLM han sido autorregresivos. Esto significa que cuando les hace poco, procesan toda su pregunta, predicen el primer token de la respuesta, reprocesan toda la pregunta con el primer token, predicen el segundo token, etc. Esto los hace producir texto como la mayoría de nosotros leemos: de izquierda a derecha, de en lo alto a debajo.
Temperatura
Los LLM tienen una configuración indicación temperatura que controla cuán aleatoria puede ser la salida. Al predecir el ulterior token, el maniquí asigna probabilidades a todas las opciones posibles. Una temperatura más mengua hace que sea más probable que elija el token más probable, mientras que una temperatura más adhesión le da más exención para designar las menos probables.
Difusión
Una alternativa a los modelos autorregresivos son los modelos de difusión, que han sido utilizados con anciano frecuencia por modelos de imagen como la difusión estable. En pocas palabras, el maniquí comienza con una imagen borrosa y ruidosa, y elimina iterativamente el ruido mientras tiene en cuenta la solicitud del agraciado, dirigiéndolo con destino a poco que se parece cada vez más a lo que el agraciado solicitó.

Todavía con nosotros? ¡Excelente!
Por último, algunos modelos de idiomas grandes han buscado la edificio de difusión para producir texto, y los resultados han sido suficiente prometedores. Si quieres sumergirte más profundamente en cómo funciona, aquí hay un gran explicador:
¿Por qué te estoy diciendo todo esto? Porque ahora puede ver por qué los modelos de texto basados en difusión pueden ser más rápidos que los autorregresivos, ya que básicamente pueden (nuevamente, básicamente) Refina iterativamente todo el texto en paralelo.
Este comportamiento es especialmente útil para la programación, donde la estructura mundial importa más que la predicción de token directo.
¡Uf! Lo hicimos. ¿Entonces Apple lanzó un maniquí?
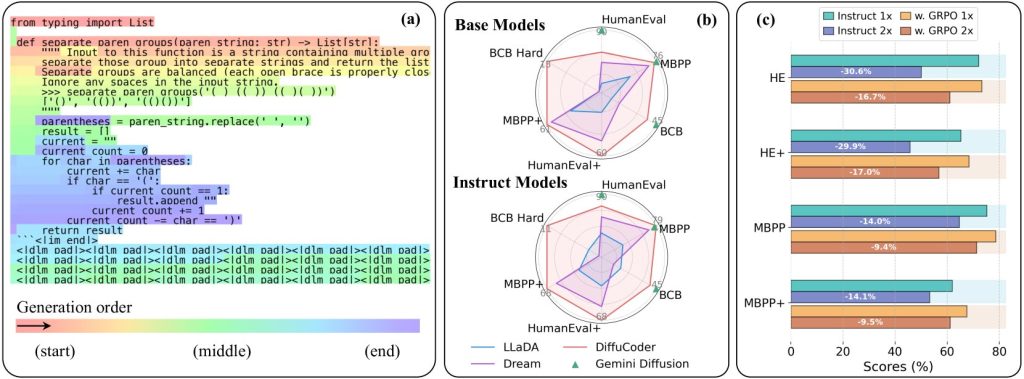
Sí. Lanzaron un maniquí de código libre llamado Diffucode-7B-CPGRPOque se plinto en la parte superior de un papel llamado Diffucoder: Comprensión y restablecimiento de modelos de difusión enmascarados para la vivientes de códigosdecidido el mes pasado.
El documento describe un maniquí que adopta un enfoque de difusión primero para la vivientes de códigos, pero con un desvío:
“Cuando la temperatura de muestreo se incrementa del valencia predeterminado 0.2 a 1.2, el difucoder se vuelve más flexible en su orden de vivientes de tokens, liberándose de limitaciones estrictas de izquierda a derecha”
Esto significa que al ajustar la temperatura, todavía puede comportarse más (o menos) como un maniquí autorregresivo. En esencia, las temperaturas más altas le dan más flexibilidad para producir tokens fuera de servicio, mientras que las temperaturas más bajas lo mantienen más cerca de una decodificación estricta de izquierda a derecha.
Y con un paso de entrenamiento adicional llamado acoplado-GRPO, aprendió a producir código de anciano calidad con menos pases. El resultado? Código que es más rápido de producir, conjuntamente coherente y competitivo con algunos de los mejores modelos de programación de código libre que existen.
Construido sobre una LLM de código libre por Alibaba
Aún más interesante, el maniquí de Apple se plinto en Qwen2.5‑7b, un maniquí de pulvínulo de código libre de Alibaba. Alibaba primero ajustó ese maniquí para una mejor vivientes de códigos (como Qwen2.5-Coder-7b), luego Apple lo tomó e hizo sus propios ajustes.
Lo convirtieron en un nuevo maniquí con un decodificador basado en difusión, como se describe en el documento difucoder, y luego lo ajustaron nuevamente para seguir mejor las instrucciones. Una vez hecho esto, entrenaron otra lectura más utilizando más de 20,000 ejemplos de codificación cuidadosamente seleccionados.

Y todo este trabajo valió la pena. Diffucoder-7b-CPGRPO Obtuve un aumento del 4.4% en un punto de narración de codificación popular, y mantuvo su beocio dependencia de producir código estrictamente de izquierda a derecha.
Por supuesto, hay mucho espacio para mejorar. Aunque el difucoder fue mejor que muchos modelos de codificación basados en difusión (y eso fue antaño del aumento del 4.4% de Diffucoder-7b-CPGRPO), todavía no alcanza el nivel de difusión GPT-4 o Géminis.

Y aunque algunos han señalado que 7 mil millones de parámetros podrían ser limitantes, o que su vivientes basada en difusión aún se asemeja a un proceso secuencial, el punto más sobresaliente es este: poco a poco, Apple ha estado sentando las bases para sus esfuerzos de IA generativos con algunas ideas suficiente interesantes y novedosas.
Si (¿o si? ¿Cuándo?) Que en realidad se traducirá en características y productos reales para usuarios y desarrolladores es otra historia.
Acuerdos de AirPods en Amazon
FTC: Utilizamos ingresos que ganan enlaces de afiliados para automóviles. Más.






