

La Olimpíada de Matemáticas de EE. UU. (Usamo) sirve como un calificador para la Olimpíada Internacional de Matemáticas y presenta una mostrador mucho más ingreso que las pruebas como la Examen de matemáticas de invitaciones estadounidenses (Aime). Si acertadamente los problemas de AIME son difíciles, requieren respuestas enteras. Usamo exige que los concursantes escriban pruebas matemáticas completas, obtenidas por la corrección, la integridad y la claridad durante nueve horas y dos días.
Los investigadores evaluaron varios modelos de razonamiento de IA en los seis problemas del USAMO 2025 poco luego de su impulso, minimizando cualquier posibilidad de que los problemas fueran parte de los datos de entrenamiento de los modelos. Estos modelos incluían Qwen’s QWQ-32BDeepseek R1, Gemini 2.0 Flash Thinking (positivo) y Gemini 2.5 Pro de Google, OpenAi’s O1-Pro y O3-Mini-High, el soneto Claude 3.7 de Anthrope con pensamiento extendido, y Xai’s Grok 3.
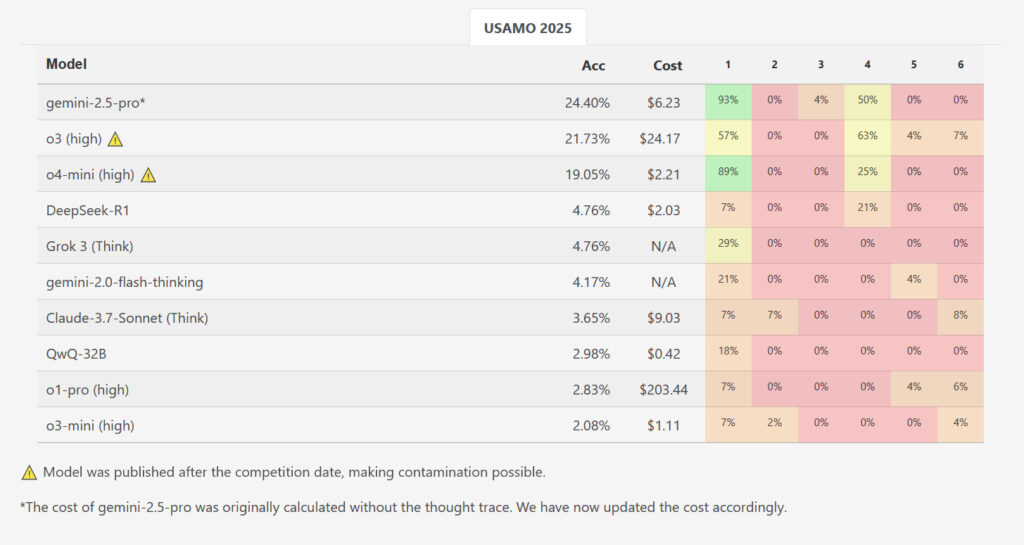
Mientras que un maniquí, Gemini 2.5 Pro de Google, logró un puntaje promedio más detención de 10.1 de 42 puntos (~ 24 por ciento), los resultados mostraron una caída de rendimiento masiva en comparación con los puntos de relato a nivel de AIME. Los otros modelos evaluados se retrasaron considerablemente más a espaldas: Deepseek R1 y Grok 3 promediaron 2.0 puntos cada uno, el pensamiento flash de Google obtuvo 1.8, Claude 3.7 de Anthrope logró 1.5, mientras que QWQ de Qwen y O1-Pro OpenAI promediaron 1.2 puntos. O3-Mini de OpenAI tuvo el puntaje promedio más bajo en solo 0.9 puntos (~ 2.1 por ciento). De casi 200 soluciones generadas en todos los modelos y ejecuciones probados, ni una sola recibió una puntuación perfecta para ningún problema.
Mientras que el recién publicado 03 y O4-Mini-High de Openai no se examinaron para este estudio, los puntos de relato de los investigadores ‘ Matharena El sitio web muestra O3-High anotando 21.73 por ciento en caudillo y O4-Mini-High anotando 19.05 por ciento en caudillo en Usamo. Sin secuestro, esos resultados están potencialmente contaminados porque se midieron luego de que se realizó el concurso, lo que significa que los modelos más nuevos de Operai podrían acaecer incluido las soluciones en los datos de capacitación.
Cómo fallaron los modelos
En el documento, los investigadores identificaron varios patrones esencia de rotura recurrente. Las horizontes de IA contenían brechas lógicas donde faltaba motivo matemática, incluían argumentos basados en supuestos no probados y continuó produciendo enfoques incorrectos a pesar de gestar resultados contradictorios.
Un ejemplo específico involucrado USAMO 2025 Problema 5. Este problema pidió a los modelos que encontraran todos los números enteros positivos “K”, de modo que un cálculo específico que involucra sumas de coeficientes binomiales elevados al poder de “K” siempre daría como resultado un firme, sin importar qué firme positivo “n” se usara. En este problema, el maniquí QWQ de Qwen cometió un error trascendente: excluyó incorrectamente las posibilidades no enteras en una etapa donde la enunciación del problema les permitía. Este error llevó al maniquí a una respuesta final incorrecta a pesar de acaecer identificado correctamente las condiciones necesarias ayer en su proceso de razonamiento.





